
A claims form arrives as a scanned PDF. A loan file lands in a shared inbox. A discharge summary gets faxed, printed, and re-keyed into three systems by two different people. Somewhere in that chain a date gets transposed, a balance gets misread, and a decision that should have taken minutes takes a week.
This is not an edge case. IDC estimates that roughly 90% of enterprise data is unstructured, and most of it lives in documents. Industry benchmarks put manual document processing at $15 to $26 per document once labor, error correction, and overhead are counted, with human error rates between 1 and 5%. The technology to close that gap exists. The reason most organizations have not closed it is the same reason most GenAI initiatives stall: extraction that works in a demo and extraction an operations team can trust in production are two very different things.
What Standard Document Automation Gets Wrong
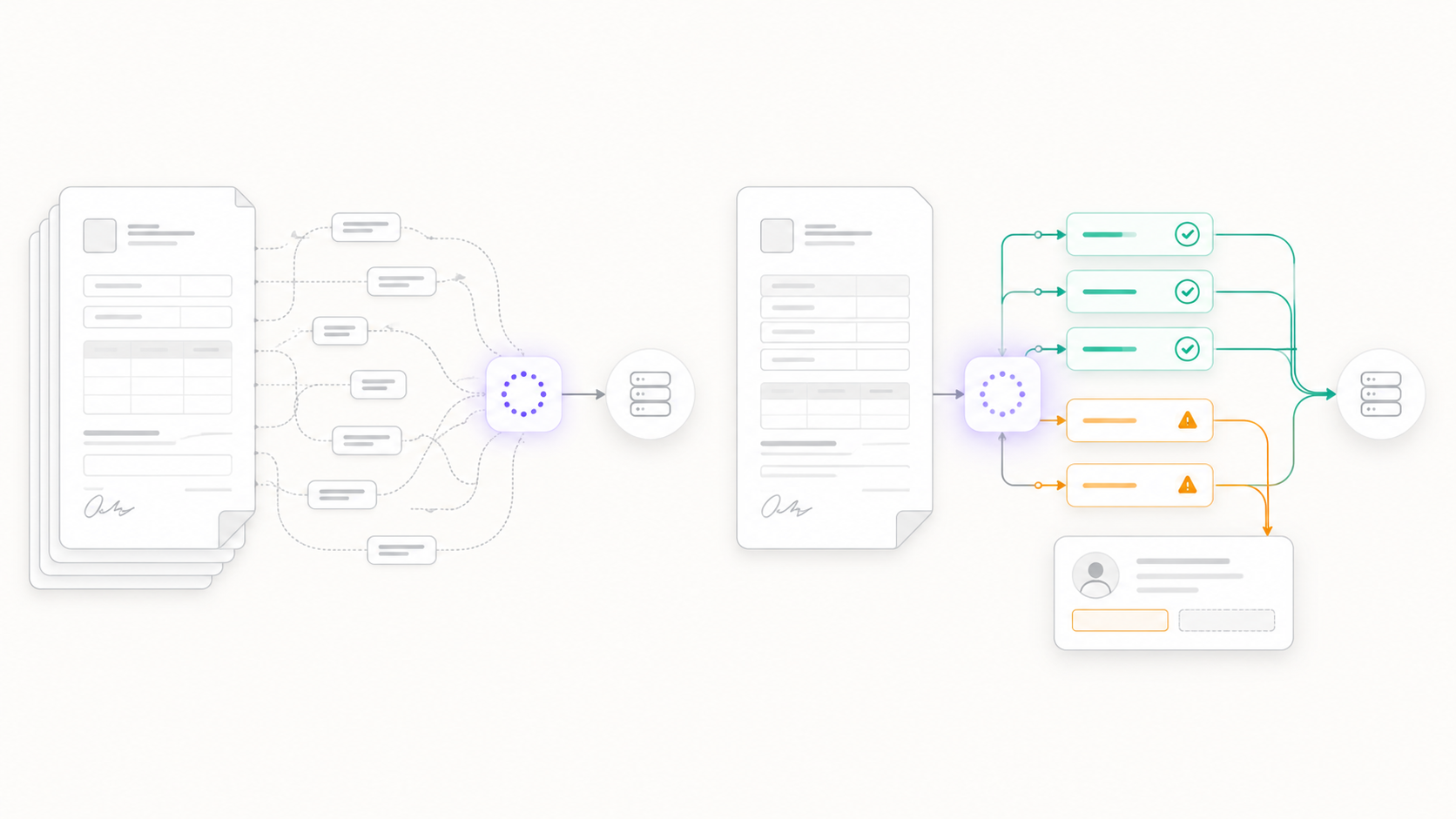
The failure modes of document automation are consistent and predictable. They just never show up in the demo.
Most document AI tools return extracted values with no usable signal about which ones to trust. A misread closing balance flows into a financial system with the same authority as a correctly read one. There is no middle ground, no confidence score, no way to let the easy extractions flow through while holding the uncertain ones for a human. Teams end up trusting everything or reviewing everything, and either option defeats the purpose.
Then there is the one-size-fits-all problem. A payslip is not a discharge summary. A purchase order is not a clinical trial consent form. Generic extraction models flatten those differences, and accuracy suffers most exactly where the stakes are highest.
Add to that pipelines that have never seen a malformed file, an oversized upload, a processing timeout, or a service throttling event. In production those are not exceptions. They are Tuesday. Without validation gates, retry logic, and failure isolation designed in from the start, the first bad batch takes the whole pipeline down with it.
The demo works. Production fails at the operational seams.
What Inferdat's IDP Solution Is
Inferdat's Intelligent Document Processing solution is a production-grade document processing pipeline built on Amazon Bedrock Data Automation (BDA), running entirely inside your AWS account. Documents go in through an upload interface, an API, or an SFTP batch feed. Validated, structured, confidence-scored data comes out. Every step in between is traced, auditable, and visible in real time.
The pipeline is orchestrated by AWS Step Functions across eight Lambda stages: input validation, blueprint resolution, BDA invocation, status polling, output processing, thumbnail generation for the review UI, review queue notification, and failure handling with dead-letter queue routing. Nothing is a black box. Every document's journey from upload to structured output is tracked in DynamoDB and visible in the pipeline UI as it happens.
The system ships with 100 extraction blueprints across 10 industry verticals: financial services, healthcare, insurance, legal, HR, retail, education, life sciences, public sector, and ISV. Each blueprint defines the exact fields to extract for that document type, so a lab report and a loan application are each processed with the logic their industry demands, not a generic model stretched across every format.
Two Things Worth Calling Out

The confidence scoring is per field, not per document. A document might extract 20 fields perfectly and 1 poorly. Per-field gating lets the 20 correct fields flow downstream immediately while routing only the uncertain field to a human reviewer. The reviewer sees the extracted value, the confidence score, and a bounding box on the document showing exactly where the value was found. They resolve it in seconds, not by re-reading the whole document. High-confidence data is never held up waiting for one uncertain field to clear.
Blueprint updates are configuration changes, not code changes. When a bank refreshes its statement template or a regulator updates a form, the extraction logic updates with a blueprint JSON change and a registry update in DynamoDB. No Step Functions redeployment, no CloudFormation change, no code release. CloudWatch anomaly detection on per-blueprint confidence scores catches accuracy drift before it reaches downstream systems.
How Inferdat Delivers IDP: The ProdWorks™ Framework
Most document automation engagements follow the same arc: a clean demo over a handful of sample documents, a build that takes longer than expected, and an operationalization phase where the real complexity surfaces. ProdWorks™ is structured to break that pattern. Every IDP engagement moves through four stages, and production-readiness is a requirement at each one.
SHOW
Before any commitment is made, Inferdat demonstrates the IDP pipeline against real documents. Upload a healthcare lab report and watch the pipeline execute in real time, each stage lighting up in sequence as it runs. See extracted fields with confidence scores appear in under 30 seconds. See a low-confidence field route to the human review queue with a bounding box showing exactly where on the document the value was found. See the cost calculator estimate what that document would cost at your actual monthly volume.
The security story is visible in the demo too. The pipeline runs in your AWS account. Documents never leave. No third-party API calls. Everything encrypted with your KMS keys. That is not a future-state claim. It is the architecture running in front of you.
PROVE
PROVE is a free, time-boxed engagement where Inferdat deploys a working IDP pipeline inside your AWS environment against one real document type from your actual operations. You are not evaluating a sandbox. You are running your documents through the full pipeline, seeing confidence scoring against your fields, and validating the human review workflow against your team's process. Everything built in PROVE carries forward into the full build. You own it from day one.
BUILD
The full build deploys the IDP solution across your document types and integrates it with your downstream systems, with the five production layers of ProdWorks™ embedded from the start:
- Observability Every document's journey is tracked in DynamoDB from upload through extraction to final output, with pipeline stage timing, confidence scores, blueprint selection, and review queue state visible in real time. Accuracy drift on any blueprint surfaces as a CloudWatch anomaly before it reaches a downstream system.
- Security KMS encryption on all S3 buckets, least-privilege IAM per Lambda function, VPC endpoints for private traffic, and a four-bucket S3 architecture separating inputs, blueprints, outputs, and logs. Documents never traverse the public internet and never leave your AWS account.
- Governance Blueprint versioning with separate DEVELOPMENT and LIVE stages means iteration never touches production workflows. Per-field confidence gating with human-in-the-loop review ensures nothing flows downstream unchecked. Every document has a complete audit trail from ingestion to output.
- Cost Control BDA pricing is transparent at $0.010 per page for custom blueprints. A built-in cost calculator estimates batch processing costs before anything runs. At 50,000 documents per month averaging 8 pages, the fully loaded cost including Step Functions, Lambda, DynamoDB, and storage runs around $4,500 per month. That is roughly nine cents per document, fully extracted, confidence-scored, and auditable.
- Reliability Step Functions Standard Workflow orchestration handles BDA jobs that run 20 or more minutes on complex documents, with retry logic and adaptive polling that adjusts based on document size. Failures route to a FIFO dead-letter queue grouped by industry for ordered replay. Input validation gates check file type, size, and page count before any AI processing begins, so malformed files never burn processing quota.
OPERATE
After go-live, Inferdat's managed operations layer keeps the IDP pipeline accurate and economical over time. Blueprint performance is monitored continuously, and confidence drift on any document type triggers review before it surfaces as a downstream complaint. New document types are added through the blueprint CI/CD process without code changes or pipeline redeployment. As document volumes grow, the serverless architecture scales without re-architecture and costs nothing to keep idle. OPERATE means the pipeline running on day one is still accurate and cost-controlled on day three hundred.
Where It Delivers Fastest
The highest-return starting points are high-volume, high-stakes document flows: claims intake in insurance, payslip and statement processing in financial services, patient record digitization in healthcare, contract and NDA review in legal, CV screening in HR, and purchase order processing in retail. These are the flows where volume makes manual processing expensive and error rates make it genuinely risky.
The outcome is straightforward. Documents that took days of manual handling become structured, validated data in minutes. Error rates drop from 1 to 5% to below 0.1%. Your team stops re-keying data and starts reviewing only the cases that actually need a human. And the economics are visible before the first document runs, not discovered on the invoice.
Inferdat's Intelligent Document Processing solution turns unstructured documents into validated, decision-ready data, production-grade from day one, backed by ProdWorks™. Talk to our team about a free PROVE on one of your document types.