
A chatbot that tells you a customer's renewal is at risk is useful. An agent that spots the risk, pulls the account history from your CRM, checks open invoices in finance, drafts the retention offer, and routes it for approval is a different category of useful entirely.
That is the promise of agentic AI, and the capability is real. So is the risk. Gartner predicts that over 40% of agentic AI projects will be canceled by the end of 2027, citing escalating costs, unclear business value, and inadequate risk controls. IDC puts the broader POC failure rate at 88%. The pattern is familiar: the demo is compelling, the capability is genuine, and the gap between a demo agent and an agent you would let near your actual business systems is where projects die.
That gap has a name: governance. And it is an engineering problem, not a prompt problem.
Why Most Agent Demos Do Not Survive a Security Review
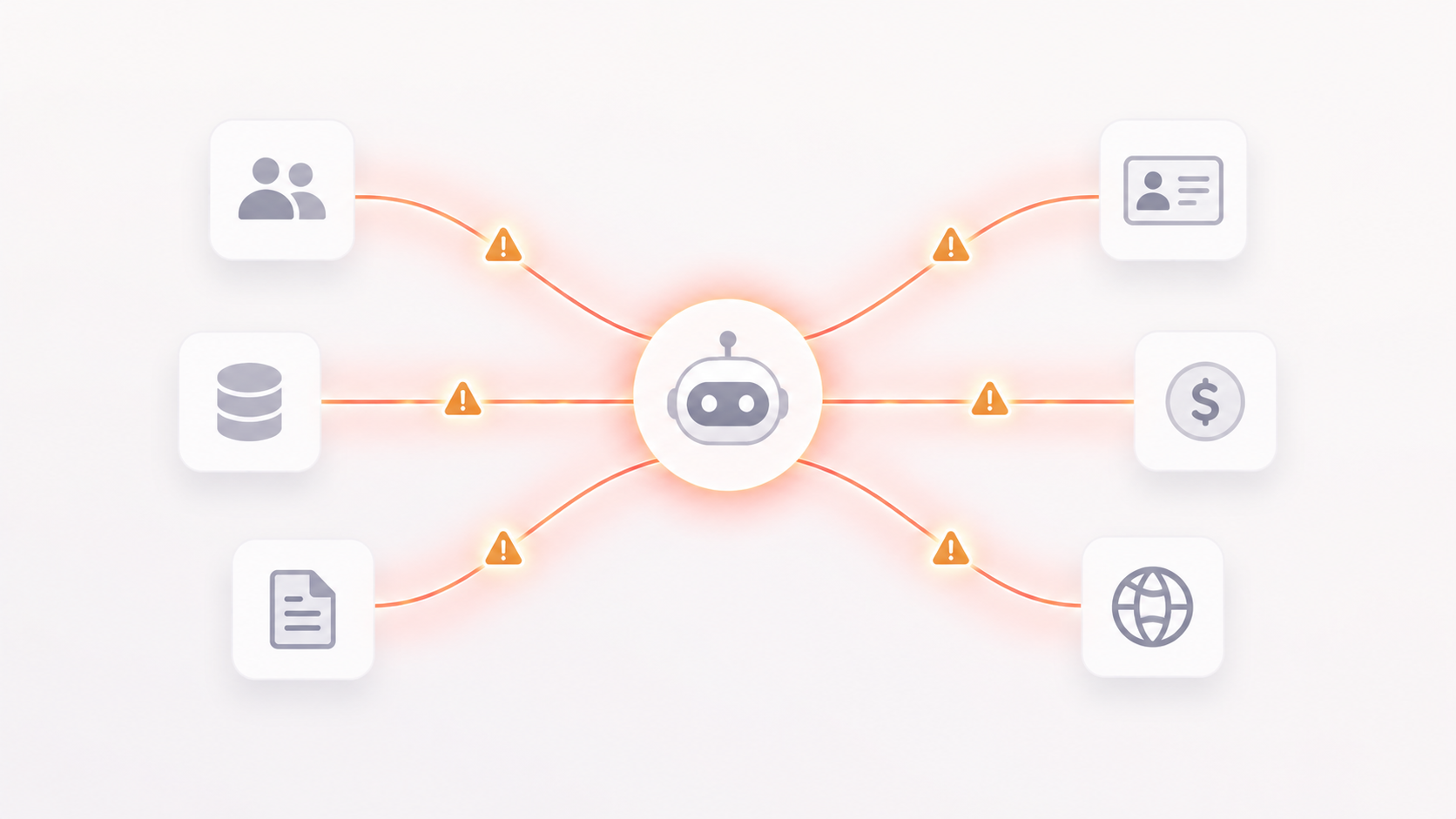
The moment an agent can call your CRM, your finance system, or the open web, every tool call is a security and correctness decision. Most agent frameworks hand the agent a list of tools and rely on the system prompt to keep it well-behaved. That is not an access control model. As the prompt injection record shows, the blast radius of a compromised agent is exactly the permission set it holds.
Role separation is the next gap. A finance analyst and a marketing manager should not have access to the same agent actions even when they ask the same question in natural language. Without access control enforced at the infrastructure layer, the agent becomes the highest-privilege employee in the company, shared by everyone.
Then there is visibility. A multi-step agent that reasons, retries, and chains tool calls can cost 10 to 100 times a single inference on edge cases and can take actions nobody anticipated. Without per-step tracing showing what the agent decided, which tools it called, and what each step cost, you are running a black box with API keys attached to your business systems. That description does not survive a security review, and it should not.
How We Build Agentic AI Differently

When Inferdat builds agentic AI systems, the governance layer is not added after the agent works. It is the architecture the agent runs inside from day one.
The system is built on Amazon Bedrock AgentCore with a single orchestrator agent that routes across enterprise tool domains through a governed MCP Gateway. We deliberately keep the architecture to one orchestrator rather than a hierarchy of sub-agents, because a single orchestrator with Cedar policies enforcing access at the Gateway boundary is simpler to trace, simpler to audit, and simpler to explain to a security team than a routing layer that delegates to sub-agents nobody can fully observe.
The access control story is enforced at the infrastructure layer, not in the prompt. Cedar RBAC policies sit between the orchestrator and every tool it can reach. When an analyst role requests financial data, the Cedar policy engine does not politely decline in natural language. It does not surface the finance tool to that role at all, and explicitly forbids the call if attempted. Prompt injection can manipulate language. It cannot override Cedar policy decisions. Every authorization decision is logged with the policy name that triggered it, making every access decision attributable, auditable, and reviewable by a security team that speaks policy, not prompt engineering.
The observability layer is built on Langfuse rather than CloudWatch alone, because CloudWatch handles infrastructure metrics but lacks the AI-specific concepts that matter for operating an agent: token tracking per LLM call, prompt versioning, cost per request, authorization scores per tool call, and the full span tree showing every decision the agent made on the way to an answer. Every request produces a trace URL. When someone asks why the agent did something, the answer is a query.
Prompts live in Langfuse rather than in code. Model configuration, temperature, and prompt text can be updated and A/B tested without a container rebuild or a deployment. A 27-test regression suite runs on every prompt change so behavioral drift surfaces before it reaches users.
What We Show You Before We Build
Most agentic AI conversations start with an architecture diagram and a list of integrations. We start by showing you a governed multi-agent system running live against real business scenarios, with the controls visible and testable in the room.
You see the orchestrator decompose a business request and route across multiple tool domains in real time, with the trace panel showing every decision and tool call as it happens. Not a black box producing an answer. Every step.
Then we switch the role. The same question asked by an admin and an analyst produces visibly different results. The Cedar policy names appear in the trace showing exactly which policy allowed or denied each tool call. You see which tools the analyst role cannot see and cannot reach, not because a prompt said so, but because the infrastructure enforces it.
Then we test the guardrails. Prompt injection attempts are caught. PII requests are blocked. Bedrock Guardrails are always on, not a future-state capability.
The goal of SHOW is to make the production controls visible and testable before a build decision is made, so the question your security team will ask in month three is answered in the first conversation.
PROVE: Your Workflows, Your Environment, Before You Commit
After SHOW, if the architecture fits, we deploy a working agentic system inside your AWS environment connected to one real business workflow at no cost through the PROVE stage of ProdWorks™. You are not evaluating a demo against seed data. You are running your actual use case through a governed multi-agent architecture, seeing Cedar policies enforced against your role structure, and validating the Langfuse trace against your own observability requirements.
Everything built in PROVE carries forward. The CDK infrastructure, the MCP Gateway configuration, the Cedar policies, the Langfuse instrumentation, all of it is reused in the full build. PROVE is not a throwaway exercise. It is the foundation.
What the Full Build Delivers
The full build connects the agent to your actual data sources, replacing seeded demo data with live systems, Salesforce, internal APIs, databases, and deploys the five ProdWorks™ production layers around it from the start.
Observability means Langfuse capturing the full trace of every request: every LLM call, tool invocation, token count, latency per span, authorization decision, and cost. Inferdat Observe bridges Langfuse with CloudWatch giving you AI-specific observability alongside infrastructure monitoring in a single operational view. Quality regression runs continuously against the 27-test evaluation suite so prompt drift surfaces before users notice it.
Security means Cedar RBAC policies enforced at the MCP Gateway boundary, scoped to the authenticated user's Cognito identity. Bedrock Guardrails screen every request for prompt injection, harmful content, and PII leakage. Lambda tools run in private VPC subnets with no public internet exposure. Least-privilege IAM per function.
Governance means every authorization decision is logged with the Cedar policy name that triggered it. Prompts are versioned and production-labeled in Langfuse, not embedded in deployment code. Model configuration is managed outside the deployment pipeline so changes do not require container rebuilds. Full audit trail per user per session.
Cost control means token counts and inference costs are attributed per request, per role, and per tool call in Langfuse. Multi-step requests that run long or retry unexpectedly surface as cost anomalies in real time. Budget alerts are configurable at the request level so there are no invoice surprises.
Reliability means AgentCore Runtime manages the agent container lifecycle without manual intervention. The MCP Gateway handles tool routing and failover. Memory persists across sessions via AgentCore Memory with per-user isolation. Cross-region inference fallback is built into the production architecture.
Where This Makes the Most Immediate Difference
The strongest starting points are coordination-heavy workflows that currently require a human to span multiple systems: account and renewal management across CRM and finance, operational triage joining monitoring data with runbooks and support tickets, marketing operations pulling performance data and executing campaign adjustments, and research workflows combining internal documents with live external information.
The outcome, when the governance is real, is an agent your organization actually expands rather than quietly retires. Cross-system tasks that took a coordinator half a day complete in minutes. Every action lands in an audit trail your compliance team can read. The security team reviews a Cedar policy document they recognize, not a prompt that promises to behave. And the question shifts from whether you can trust it to what else you can hand it.
Inferdat builds production-grade agentic AI on AWS: orchestrated agents with governed tool access, Cedar RBAC, Langfuse observability, and full audit trails, backed by ProdWorks™. Talk to our team about a SHOW demo on your own workflows.