
The answer exists somewhere in your organization. It is in a policy document on SharePoint, a product spec in Confluence, a compliance manual someone exported to a shared drive in 2023. The person who needs it right now will spend twenty minutes searching, give up, and email the one colleague who always seems to know, who will spend their own twenty minutes finding it.
McKinsey research found that knowledge workers spend nearly two hours a day searching for and gathering information. The retrieval mechanism is people. The institutional knowledge is there. The problem is getting to it reliably, quickly, and in a way that holds up when the answer actually matters.
RAG, retrieval-augmented generation, is the right architecture for this problem. But most teams discover the hard way that RAG in a demo and RAG in production are separated by an operational gap nobody warned them about.
What Standard RAG Gets Wrong in Production
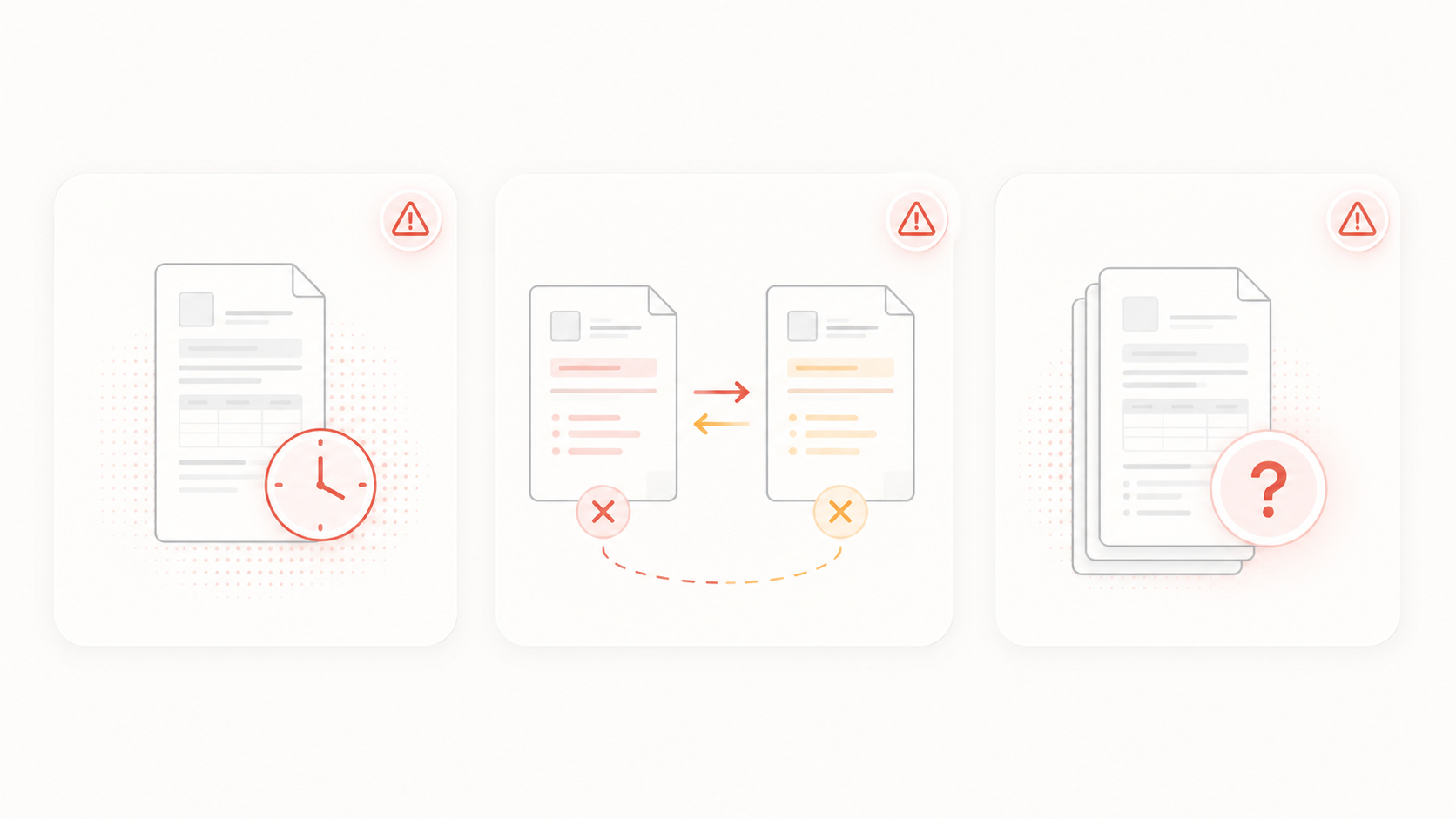
The demo is easy. Connect a handful of documents to a language model, ask it questions, get cited answers. Everyone is impressed. Then it goes to production, and the real questions start.
What happens when a regulatory guideline is updated and the old version is still in the knowledge base serving the old answer? What happens when two internal policies contradict each other on the same eligibility threshold and the AI picks one at random? Who approved that document for indexing? What did the assistant tell a user about a treatment protocol three months ago, and from which version of which document? Is the knowledge base actually current, and how would anyone know if it was not?
These are not edge cases. They are the operational realities of running an AI knowledge system in a regulated environment. They are also the reasons most enterprise RAG deployments silently degrade after month three, not because the technology failed, but because nobody built the operational layer around it.
Uploading documents to a vector store and calling it a knowledge base is not the same thing as running a knowledge base in production. The difference is everything that has to work around the retrieval loop for it to remain accurate, trustworthy, and auditable over time.
How We Think About Building Knowledge Assistants
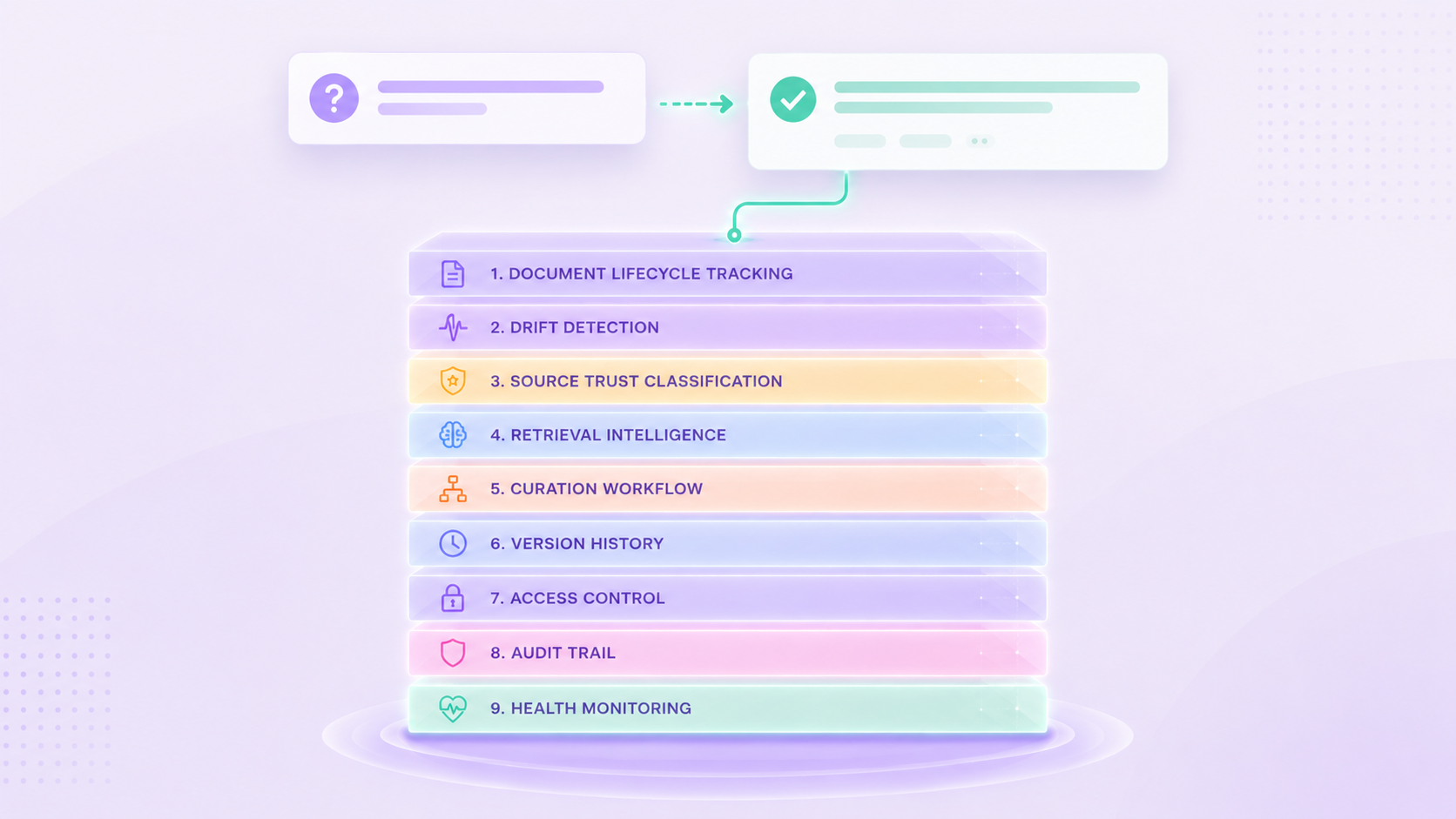
Inferdat's Knowledge Assistant is built on a nine-layer operational framework that addresses each of these failure modes directly. Here is a slice of what that looks like in practice.
Every document in the system has a tracked lifecycle state: uploaded, pending approval, indexing, indexed, or failed. Nothing enters the knowledge base without passing through an approval gate. In a contributor role, documents queue for admin review before a single passage becomes retrievable. In high-stakes environments like healthcare or financial services, that approval control is the difference between a knowledge base you can trust and one you cannot.
Drift detection runs automatically when a document is re-uploaded. Rather than relying on simple text comparison, the system uses an LLM-as-judge approach to identify material factual changes between versions. When a hypertension guideline changes the recommended blood pressure target from 140/90 to 130/80, the system surfaces that as a high-severity drift event, not a formatting update. When two documents in the same vertical disagree on an eligibility threshold, conflict detection flags the contradiction before it can surface as an inconsistent answer to a user.
Every document also carries a trust tier, authoritative, standard, or informational, that travels with every citation at retrieval time. An official regulatory guidance document and an internal working draft do not carry the same weight. The system reflects that.
Each industry vertical operates in a structurally isolated knowledge base. Healthcare documents and financial services documents are not separated by a metadata filter that could be misconfigured. They are in entirely separate Bedrock Knowledge Bases with their own vector indices. Cross-vertical retrieval is architecturally impossible.
This is a fraction of the operational surface area the framework covers. The point is not the feature list. The point is that none of this exists in a standard RAG deployment, and all of it matters before you can responsibly put an AI knowledge assistant in front of users in a regulated environment.
How Inferdat Delivers This: The ProdWorks™ Framework
Understanding what production RAG requires and having it built and ready to demonstrate are different things. Inferdat moves through four stages with every Knowledge Assistant engagement, and the operational framework is present from the first conversation.
SHOW
Before any commitment is made, Inferdat demonstrates the Knowledge Assistant against real operational scenarios, not a polished demo dataset. You see drift detection fire on an actual document update. You see conflict detection surface a genuine contradiction between two policy versions. You see the approval workflow, the freshness scoring, and the audit trail working together in a system that reflects what your production environment would actually look like. The goal of SHOW is to make the operational realities visible before a dollar is spent on a build.
PROVE
PROVE is a free, time-boxed engagement where Inferdat deploys a working Knowledge Assistant inside your AWS environment against one real knowledge domain, with everything built remaining yours. You are not evaluating a demo. You are running your actual documents through the full operational framework, seeing drift and conflict detection against your content, and validating the approval and audit workflows against your compliance requirements. Everything built in PROVE carries forward into the full build.
BUILD
The full build deploys the Knowledge Assistant across your document corpus and integrates it with your existing sources and downstream systems, with the five production layers of ProdWorks™ embedded from the start:
- Observability Query volume, answer confidence, citation accuracy, retrieval latency, freshness debt scores, and conflict counts are tracked continuously across every vertical. Knowledge base health is a live dashboard, not a periodic audit.
- Security Access controls, PII redaction, content filtering, and a complete audit trail are built into the architecture. Approval gates prevent unapproved content from entering the knowledge base at the ingestion layer, not the retrieval layer, which is a stronger guarantee.
- Governance Every response is traceable from question to retrieved passage to source document version. Conflict detection and drift scoring run continuously. Regulated industries get the answer trail and the content integrity controls that compliance requirements demand.
- Cost Control LLM invocations for drift and conflict detection are bounded by a hybrid gate chain that skips expensive model calls when content has not materially changed. Processing costs are tracked and visible continuously, not discovered at billing time.
- Reliability The system is fully serverless and scales without re-architecture. Document ingestion includes validation gates so malformed uploads never corrupt the index. Version history is maintained natively in S3 so point-in-time reconstruction of knowledge base state is always available.
OPERATE
After go-live, Inferdat's managed operations layer keeps the Knowledge Assistant accurate and current over time. Drift scans run on a scheduled basis with alerting when documents approach their vertical-specific freshness threshold. Conflict detection runs continuously and surfaces contradictions as they emerge rather than after they cause an incident. New document sources and verticals are onboarded as the knowledge base grows. Retrieval regression testing validates that answer quality holds as the corpus changes. OPERATE means the system you deployed on day one is still trustworthy on day three hundred.
Where This Makes the Most Immediate Difference
The highest-return starting points are knowledge domains where questions are frequent, documents change regularly, and the cost of a wrong answer is high. Compliance and regulatory knowledge in financial services and healthcare. Clinical protocols and treatment guidelines in life sciences. Contract and policy repositories in legal. Product and API documentation for technical support teams. Onboarding knowledge bases where new employees ask the same questions your senior people are tired of answering.
The outcome is not just faster answers. It is a knowledge base you can trust to stay accurate, an audit trail that satisfies compliance requirements, and an operational framework that surfaces problems before they reach users. That is what production RAG actually requires. It is also what we build with you, and what we can show you running on your own documents before a dollar is committed to a full engagement.
Inferdat's Enterprise Knowledge Assistant delivers cited, accurate answers from your own documents with a nine-layer operational framework that keeps your knowledge base current, conflict-free, and audit-ready. Talk to our team about a free PROVE on one of your knowledge domains.