
The dashboard loaded fine this morning. The numbers were wrong.
Somewhere upstream, a source system changed a column type, a batch landed with malformed records, and the pipeline did exactly what most pipelines do with bad data: nothing. No failure, no alert. The records flowed through every stage and into the quarterly report. Now your AI models are training on them too.
Gartner puts the average cost of poor data quality at $12.9 million per organization per year. The mechanism is rarely dramatic. It is silent. And it compounds, because every analytics initiative and every AI model downstream inherits whatever the pipeline chose not to catch.
The Maintenance Tax Nobody Budgets For
Data engineering teams spend roughly 80% of their time maintaining existing pipelines and 20% building new ones. That ratio is not a staffing problem. It is an architecture problem.
In most ETL estates, every table has its own hand-written transformation code. Business rules are hardcoded inside PySpark jobs that only engineers can read, modify, or audit. When a source system renames a field, someone rewrites code. When a new data source needs onboarding, someone builds a new pipeline. When the engineer who understood table 47's quirks leaves, that understanding leaves with them.
The result is a pipeline estate that grows in breadth but shrinks in comprehension. Adding sources gets slower the more sources you have, which is exactly the wrong direction for a team trying to expand analytics coverage or feed more data into AI systems.
How We Think About Building Data Pipelines
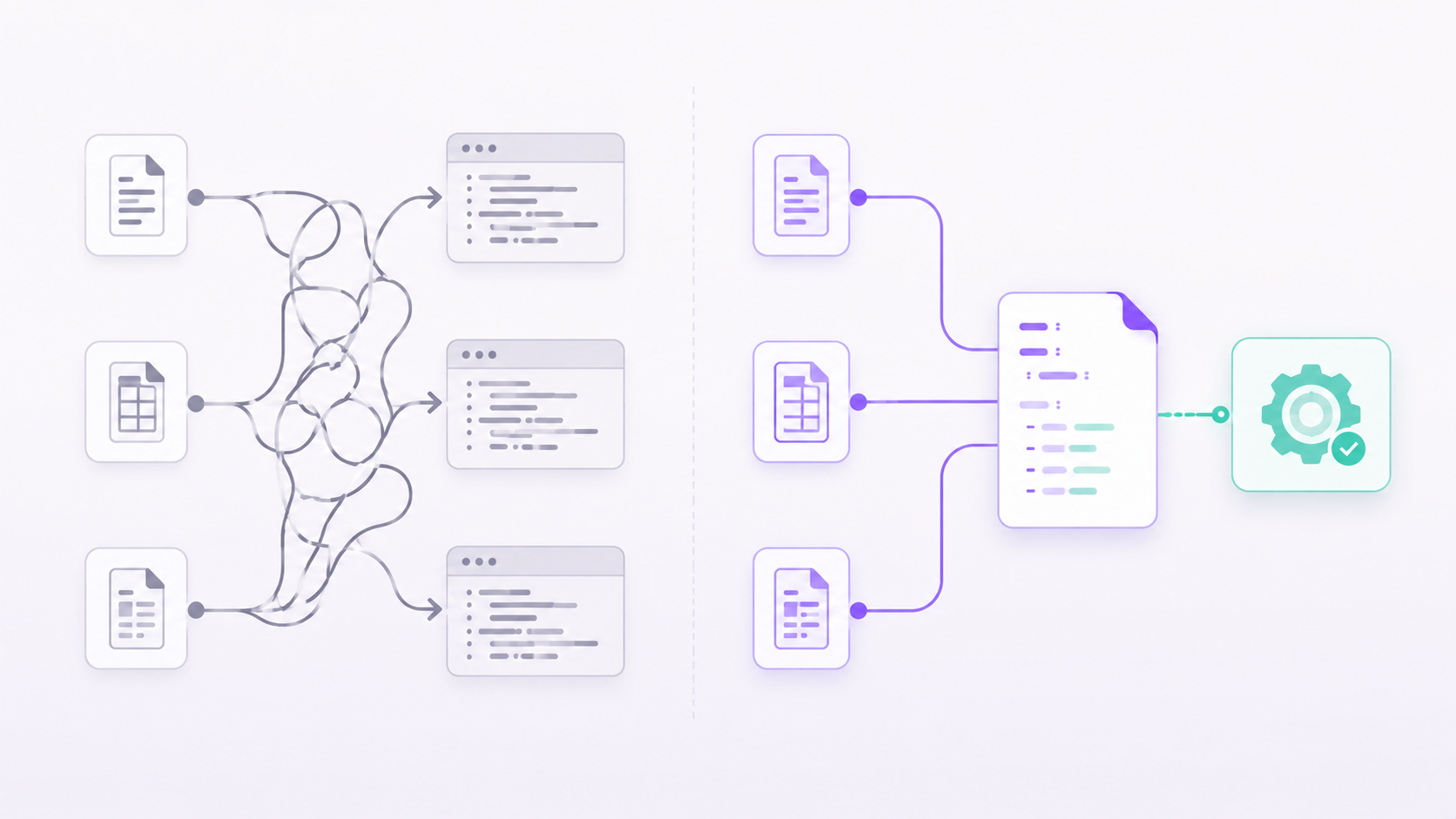
The single architectural decision that changes the maintenance equation is separating business rules from execution logic. When we build data pipelines for customers, every table's schema, quality rules, transformations, and enrichments are declared in versioned YAML contracts. The PySpark execution engines are generic and reusable across every table. Adding a new dataset means writing a contract file, not building a pipeline.
This is not a subtle difference in developer experience. It means a business analyst can read and review the rules governing a dataset. A compliance team can audit them without opening a codebase. A new engineer can understand the full data estate in days rather than months. And onboarding a new source, something that takes weeks in a bespoke ETL environment, becomes a same-day task.
The contracts are versioned, so the exact rules that processed any given dataset on any given day are permanently attributable. When an auditor asks what validation logic was applied to the March billing run, the answer is a version number and a YAML file, not an archaeological dig through Git history.
Underneath the contracts sits a three-layer medallion architecture orchestrated by AWS Step Functions across AWS Glue ETL jobs. The Raw layer holds an exact copy of source data, the preserved source of truth. The Prepared layer is where data quality validation runs against the contract. The Curated layer applies business logic enrichments that make data analytics-ready and ML-ready. Amazon Athena provides serverless SQL access to any layer at any time, so every stage of data's journey is independently queryable.
What We Show You Before We Build
Most data pipeline conversations start with a requirements document and end months later with a pipeline the business has never seen run against real data. We do it differently.
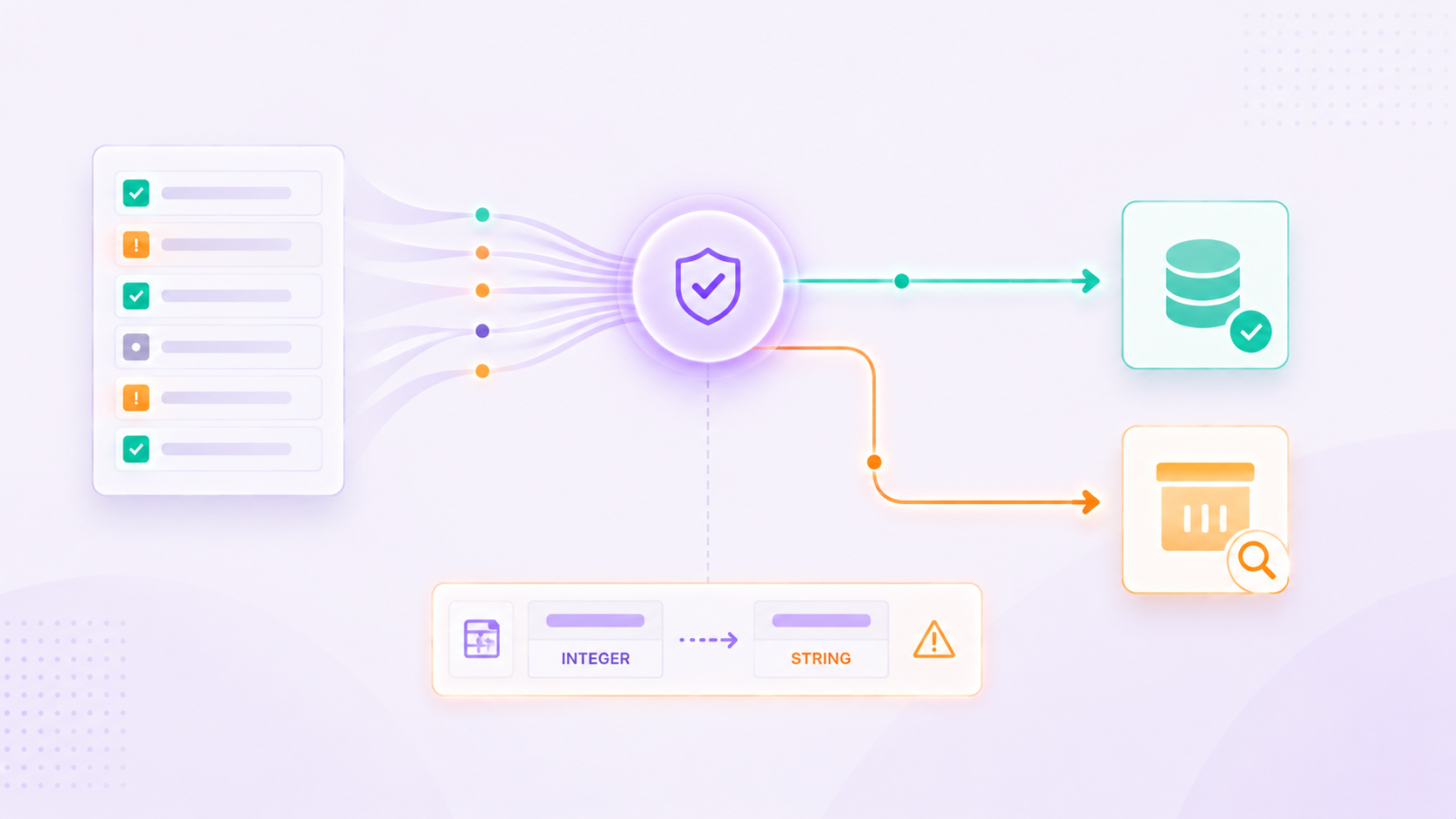
Before any build commitment is made, we show you exactly what a production-grade pipeline looks like running against realistic scenarios, including the failure modes most demos skip entirely. We can trigger a schema type change live and show you how the pipeline classifies it, quarantines affected records, logs a drift event, and keeps processing without crashing. We can trigger a major quality event where a significant portion of records fail validation and show you how the quarantine zone captures them with the reason for failure attached, while valid records continue flowing uninterrupted.
We show you the contract file that governs each table. We show you the audit trail with every run's unique ID, record counts, quality scores, and contract version. We show you the quality score dashboard that makes data health visible without opening a terminal.
The point is not the demo itself. It is that you understand exactly what you are getting before we build it, and you can see it running on infrastructure that mirrors what production will look like.
PROVE: Your Data, Your Environment, Before You Commit
After SHOW, if the architecture fits, we deploy a working pipeline inside your AWS environment against one of your actual data sources at no cost through the PROVE stage of ProdWorks™. You run your own data through the medallion architecture. You see your own schema drift events. You validate quarantine thresholds against your real data quality profile. You query your own data across layers in Athena.
Everything built in PROVE carries forward into the full build. The Terraform infrastructure, the Glue jobs, the contract engine, the audit system are all reused. From PROVE to production is a contract-writing exercise against your remaining data sources, not a rebuild from scratch. That is what compresses a six-month data engineering program into weeks.
What the Full Build Delivers
When we build the full pipeline, the five ProdWorks™ production layers are embedded from the start rather than added as afterthoughts.
Observability means CloudWatch custom metrics and live dashboards tracking quality score trends per layer, with alarms on the signals that precede failures rather than the failures themselves. Every pipeline run produces a complete audit record traceable from source to consumption layer.
Security means KMS encryption across all S3 buckets, least-privilege IAM per Glue job, and Terraform remote state that is encrypted, locked, and versioned from day one. For regulated industries, AWS Lake Formation adds column-level and row-level access controls and PII handling.
Governance means versioned contracts in version control, contract validation in the CI/CD pipeline, and a full audit trail per run that satisfies compliance requirements without building a separate reporting layer.
Cost control means a serverless architecture that costs nothing when idle and scales from Glue Python Shell for standard workloads to EMR Serverless for billion-row volumes using the same PySpark engines, no code changes, no re-architecture. In production environments with 100-plus tables and cross-dependencies, we use MWAA with manifest-driven DAG auto-generation so the orchestration scales with the estate.
Reliability means Step Functions orchestration with idempotent reruns, quarantine-based failure isolation so one bad batch never takes down the pipeline, and in production cross-region replication and a full CI/CD pipeline with contract validation and security scanning across environments.
Where This Makes the Most Immediate Difference
The clearest return comes from data flows where quality has direct consequences: healthcare and life sciences data subject to regulatory audit, financial reporting pipelines where a silent error is a restatement risk, customer data consolidations feeding AI models, and organizations carrying a backlog of data sources that bespoke ETL has made too expensive to onboard.
The outcome is a pipeline whose numbers you can defend. Every record either met its contract or sits in quarantine with an explanation. Every figure traces to its source in minutes. New data sources onboard in days. And every AI initiative downstream starts from validated data rather than inheriting a quality problem that was never going to get fixed.
Inferdat builds contract-driven, quality-gated data pipelines on AWS, production-grade from day one, backed by ProdWorks™. Talk to our team about a free PROVE on one of your data sources.